Scaling LLM inference with Ray and vLLM

Large Language Models (LLM) are becoming increasingly popular in many AI applications. These powerful language models are widely used to automate a series of tasks, improve customer service, and generate domain-specific content among many other usecases. At Navatech, LLM's are core of our conversational health and safety platform, powering various agents providing in-context health and safety information to our users and delivering the right content.
However, serving these fine-tuned LLMs at scale comes with challenges. Those models are computationally consuming. Their sizes are much larger than the traditional microservices, making it hard to archive high throughput serving and low cold start scaling.

Continuous Batching to Rescue
Due to the large GPU memory footprint and compute cost of serving LLMs, ML engineers often treat LLMs like "black boxes" that can only be optimized with internal changes such as quantization and custom CUDA kernels. However, this is not entirely the case. Because LLMs iteratively generate their output, and because LLM inference is often memory and not compute bound, there are system-level batching optimizations that make 8-10x or more differences in real-world workloads.
One recent such proposed and widely used optimization technique is continuous batching, also known as dynamic batching, or batching with iteration-level scheduling. We experimented to see the performance optimization it brings in at a production workload. We will get into details below, including how we simulate a production workload, but to summarize our findings:
- Up to 23x throughput improvement using continuous batching and continuous batching-specific memory optimizations (using vLLM).
- 8x throughput over naive batching by using continuous batching (both on Ray Serve and Hugging Face’s text-generation-inference).
- 4x throughput over naive batching by using an optimized model implementation (NVIDIA’s FasterTransformer).
GPUs are massively-parallel compute architectures, with compute rates (measured in floating-point operations per second, or flops) in the teraflop (A100) or even petaflop (H100) range. Despite these staggering amounts of compute, LLMs struggle to achieve saturation because so much of the chip’s memory bandwidth is spent loading model parameters. Batching is one way to improve the situation; instead of loading new model parameters each time you have an input sequence, you can load the model parameters once and then use them to process many input sequences. This more efficiently uses the chip’s memory bandwidth, leading to higher compute utilization, higher throughput, and cheaper LLM inference.
The industry recognized the inefficiency and came up with a better approach. Orca: A Distributed Serving System for Transformer-Based Generative Models is a paper presented in OSDI ‘22 tackles this problem. Instead of waiting until every sequence in a batch has completed generation, Orca implements iteration-level scheduling where the batch size is determined per iteration. The result is that once a sequence in a batch has completed generation, a new sequence can be inserted in its place, yielding higher GPU utilization than static batching.

Reality is a bit more complicated than this simplified model: since the prefill phase takes compute and has a different computational pattern than generation, it cannot be easily batched with the generation of tokens. Continuous batching frameworks currently manage this via hyperparameter: waiting_served_ratio, or the ratio of requests waiting for prefill to those waiting end-of-sequence tokens.
PagedAttention and vLLM
PagedAttention is a new attention mechanism implemented in vLLM (GitHub). It takes inspiration from traditional OS concepts such as paging and virtual memory. They allow the KV cache (what is computed in the “prefill” phase, discussed above) to be non-contiguous by allocating memory in fixed-size “pages”, or blocks. The attention mechanism can then be rewritten to operate on block-aligned inputs, allowing attention to be performed on non-contiguous memory ranges.
This means that buffer allocation can happen just-in-time instead of ahead-of-time: when starting a new generation, the framework does not need to allocate a contiguous buffer of size maximum_context_length. Each iteration, the scheduler can decide if it needs more room for a particular generation, and allocate on the fly without any degradation to PagedAttention’s performance. This doesn’t guarantee perfect utilization of memory ( limited to under 4%, only in the last block), but it significantly improves upon wastage from ahead-of-time allocation schemes used widely by the industry today.
Altogether, PagedAttention + vLLM enable massive memory savings as most sequences will not consume the entire context window. These memory savings translate directly into a higher batch size, which means higher throughput and cheaper serving.
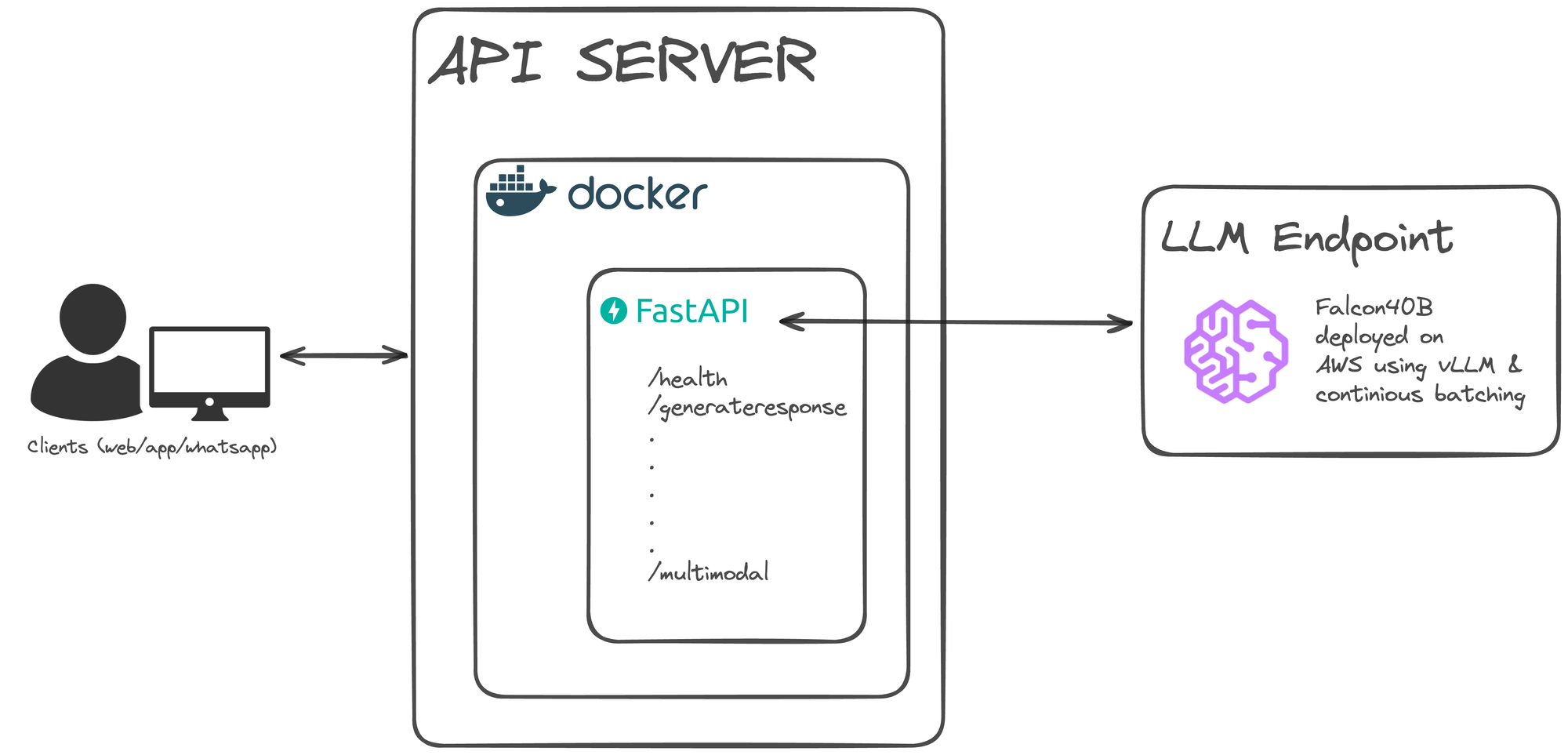
Production Environment -
We scaled the production setup we mentioned in our previous blog, and deployed the Falcon LLM in a EKS cluster running ray-serve and vLLM moving away from a managed SageMaker Endpoint,
Benchmarking results: Throughput
Based on our understanding of static batching, we expect continuous batching to perform significantly better when there is higher variance in sequence lengths in each batch. To test this, we run a throughput benchmark four times for static and continious batching, configured our model to always emit a per-sequence generation length by ignoring the end-of-sequence token and configuring max_tokens. We then use a simple asyncio Python benchmarking script to submit HTTP requests to our model server. The benchmarking script submits all requests in burst fashion, so that the compute is saturated.
The results are as follows:

What is most impressive here is vLLM. For each dataset, vLLM more than doubles performance compared to naive continuous batching. We have not analyzed what optimization contributes the most to vLLM performance the most, but we suspect vLLM’s ability to reserve space dynamically instead of ahead-of-time allows vLLM to dramatically increase the batch size.
We plot these performance results relative to naive static batching:

Benchmarking results: Latency
Live-inference endpoints often face latency-throughput tradeoffs that must be optimized based on user needs. We benchmark latency on a realistic workload and measure how the CDF of latencies changes with each framework.
Similar to the throughput benchmark, we configure the model to always emit a specified amount of tokens specified per-request. We measure latencies at both QPS=1 and QPS=4 to see how the latency distribution changes as load changes.

We see that while improving throughput, continuous batching systems also improve median latency. This is because continuous batching systems allow for new requests to be added to an existing batch if there is room, each iteration. But how about other percentiles? In fact, we find that they improve latency across all percentiles:

The reason why continuous batching improves latency at all percentiles is the same as why it improves latency at p50: new requests can be added regardless of how far into generation other sequences in the batch are. However, like static batching, continuous batching is still limited by how much space is available on the GPU. As your serving system becomes saturated with requests, meaning a higher on-average batch size, there are less opportunities to inject new requests immediately when they are received. We can see this as we increase the average QPS to 4:

Anecdotally, we observe that vLLM becomes saturated around QPS=8 with a throughput near 1900 token/s. To compare these numbers apples-to-apples to the other serving systems requires more experimentation; however we have shown that continuous batching significantly improves over static batching by 1) reducing latency by injecting new requests immediately when possible, and 2) enable advanced memory optimizations (in vLLM’s case) that increase the QPS that the serving system can handle before becoming saturated.
Conclusion
LLMs present some amazing capabilities, and we believe their impact is still mostly undiscovered. We have shared how a new serving technique, continuous batching, works and how it outperforms static batching. It improves throughput by wasting fewer opportunities to schedule new requests, and improves latency by being capable of immediately injecting new requests into the compute stream. We are excited to see what people can do with continuous batching, and where the industry goes from here.
Join Our Team of Innovators!

Are you a passionate developer seeking exciting opportunities to shape the future of technology? We're looking for talented individuals to join our dynamic ML/DS team at Navatech Group. If you're eager to be part of groundbreaking projects and make a real impact, we want to hear from you!
Send your resume to careers@navatechgroup.com and take the first step toward a rewarding career with us. Join Navatech Group today and be at the forefront of innovation!