Breaking Boundaries: Leveraging Web Assembly and Mediapipe for running SLM's offline on the Edge
Leveraging the power of WebAssembly (WASM) and Mediapipe, we are reimagining health and safety and revolutionizing the way SLM's are deployed, enabling them to run offline on mobile devices.





In a world where access to crucial health and safety information can mean the difference between life and death, the need for universal accessibility knows no bounds. At NavaTech, we are driven by a singular mission: to ensure that everyone, regardless of their location or internet connectivity, has access to vital health and safety resources. Our innovative approach combines cutting-edge technology with a commitment to global safety. Leveraging the power of WebAssembly (WASM) and Mediapipe, we are reimagining health and safety and revolutionizing the way SLM's are deployed, enabling them to run offline on mobile devices. At Navatech Group, our startup is dedicated to making AI more accessible by breaking down communication barriers. Our mission centers on bridging the digital divide between urban centers and remote areas, ensuring that AI technology is available and beneficial to all, regardless of location or connectivity. By focusing on accessible AI, we are setting new global standards for ensuring safety and ease of access to advanced technologies. This commitment to accessibility not only fosters inclusivity but also enhances connectivity across diverse communities worldwide.

Google released Mediapipe LLM APU on March 7th 2024, and we had been trying to fast follow the innovation and make SLMs available offline for our users, In this blog, we will delve into the intricacies of our approach, exploring the challenges of ensuring health and safety information reaches every corner of the globe. We'll discuss the role of WebAssembly and Mediapipe in enabling offline SLM deployment on mobile devices and examine the technical aspects of how these technologies work together to achieve our mission. Furthermore, we'll highlight real-world scenarios where our offline edge solutions have made a tangible impact, from bustling city centers to remote sites with limited connectivity. Join us on this journey as we unlock the potential of technology to empower safety everywhere.
How LLM's are deployed today?
In a typical Large Language Model (LLM) deployment scenario, the LLM is hosted on a public cloud infrastructure like AWS or GCP and exposed as an API endpoint. This API serves as the interface through which external applications, such as mobile apps on Android and iOS devices or Web Serices, interact with the LLM to perform natural language processing tasks. When a user initiates a request through the mobile app, the app sends a request to the API endpoint using data, specifying the desired task, such as text generation or sentiment analysis.
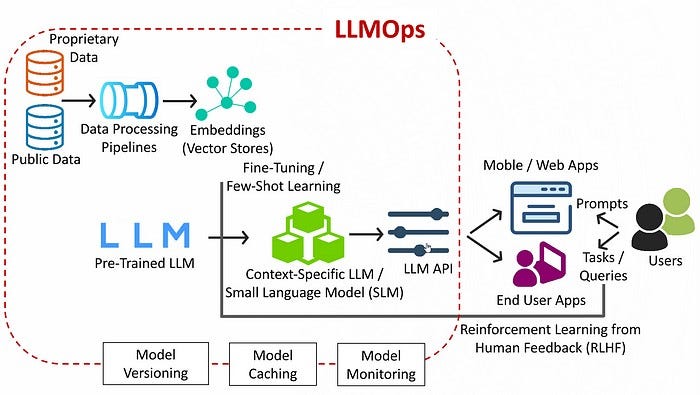
The API processes the request, utilizing the LLM to perform the required task, and returns the result to the mobile app. This architecture enables seamless integration of LLM capabilities into mobile applications, allowing users to leverage advanced language processing functionalities directly from their devices while offloading the computational burden to the cloud infrastructure.
To overcome the limitations of relying on internet connectivity and ensure users have the flexibility and ease to interact with their safety copilot even in remote locations or locations where internet isn’t available like basements or underground facilities while safeguarding privacy, the optimal solution is to run Large Language Models (LLMs) on-device, offline. By deploying LLMs directly on users' devices, such as mobile phones and tablets, we eliminate the need for continuous internet access and the associated back-and-forth communication with remote servers. This approach empowers users to access their safety copilot anytime, anywhere, without dependency on network connectivity.
What are Small Language Models (SLMs) ?
Small Language Models (SLMs) represent a focused subset of artificial intelligence tailored for specific enterprise needs within Natural Language Processing (NLP). Unlike their larger counterparts like GPT-4, SLMs prioritize efficiency and precision over sheer computational power. They are trained on domain-specific datasets, enabling them to navigate industry-specific terminologies and nuances with accuracy. In contrast to Large Language Models (LLMs), which may lack customization for enterprise contexts, SLMs offer targeted, actionable insights while minimizing inaccuracies and the risk of generating irrelevant information. SLMs are characterized by their compact architecture, lower computational demands, and enhanced security features, making them cost-effective and adaptable for real-time applications like chatbots. Overall, SLMs provide tailored efficiency, enhanced security, and lower latency, addressing specific business needs effectively while offering a promising alternative to the broader capabilities of LLMs.
Why running SLM's offline at edge is a challenge?
Running small language models (SLMs) offline on mobile phones enhances privacy, reduces latency, and promotes access. Users can interact with llm-based applications, receive critical information, and perform tasks even in offline environments, ensuring accessibility and control over personal data. Real-time performance and independence from centralized infrastructure unlock new opportunities for innovation in mobile computing, offering a seamless and responsive user experience. However, running SLMs offline on mobile phones presents several challenges due to the constraints of mobile hardware and the complexities of running LLM tasks. Here are some key challenges:
- Limited Processing Power: Mobile devices, especially smartphones, have limited computational resources compared to desktop computers or servers. SLMs often require significant processing power to execute tasks such as text generation or sentiment analysis, which can strain the capabilities of mobile CPUs and GPUs.
- Memory Constraints: SLMs typically require a significant amount of memory to store model parameters and intermediate computations. Mobile devices have limited RAM compared to desktops or servers, making it challenging to load and run large language models efficiently.
- Battery Life Concerns: Running resource-intensive tasks like NLP on mobile devices can drain battery life quickly. Optimizing SLMs for energy efficiency is crucial to ensure that offline usage remains practical without significantly impacting battery performance.
- Storage Limitations: Storing large language models on mobile devices can be problematic due to limited storage space. Balancing the size of the model with the available storage capacity while maintaining performance is a significant challenge.
- Update and Maintenance: Keeping SLMs up to date with the latest improvements and security patches presents challenges for offline deployment on mobile devices. Ensuring seamless updates while minimizing data usage and user inconvenience requires careful planning and implementation.
- Real-Time Performance: Users expect responsive performance from mobile applications, even when running complex NLP tasks offline. Optimizing SLMs for real-time inference on mobile devices is crucial to provide a smooth user experience.
Enabling on-device LLM's with Mediapipe and Web Assembly

TensorFlow Lite revolutionized on-device ML in 2017, and MediaPipe expanded its capabilities further in 2019. Now, with the release of experimental MediaPipe LLM Inference API, developers can run Large Language Models (LLMs) entirely on-device. This breakthrough, supporting Web, Android, and iOS, facilitates integration and testing of popular LLMs like Gemma, Phi 2, Falcon, and Stable LM. This latest release marks a paradigm shift, empowering developers to deploy Large Language Models fully on-device across various platforms. This capability is particularly groundbreaking considering the substantial memory and compute requirements of LLMs, which can be over a hundred times larger than traditional on-device models. The achievement is made possible through a series of optimizations across the on-device stack, including the integration of new operations, quantization techniques, caching mechanisms, and weight sharing strategies. These optimizations ranging from weights sharing, XNNPack, and our GPU-accelerated runtime for efficient on-device LLM inference to custom operators, were crucial in balancing computational demands and memory constraints, ultimately enhancing performance across platforms.
But what is WebAssembly?
WebAssembly (Wasm) emerged as a game-changer, originally designed for web browsers to enable the execution of non-JavaScript code seamlessly. Its binary format, compatible with multiple programming languages, offers significant advantages: it runs on any operating system and processor architecture and operates within a highly secure sandbox environment. Beyond browsers, Wasm finds utility in cloud computing, enabling providers like AWS to lease Wasm runtimes to customers for serverless-style workloads. In the realm of AI, Wasm offers a compelling solution for resource-intensive tasks like generative AI. By efficiently time-slicing GPU access and ensuring platform neutrality, Wasm optimizes GPU usage and facilitates seamless deployment across diverse hardware environments. Advances such as the WebAssembly Systems Interface – Neural Networks (WASI-NN) standard further enhance its capabilities, promising a future where Wasm plays a pivotal role in democratizing access to AI-grade compute power and optimizing AI workloads.
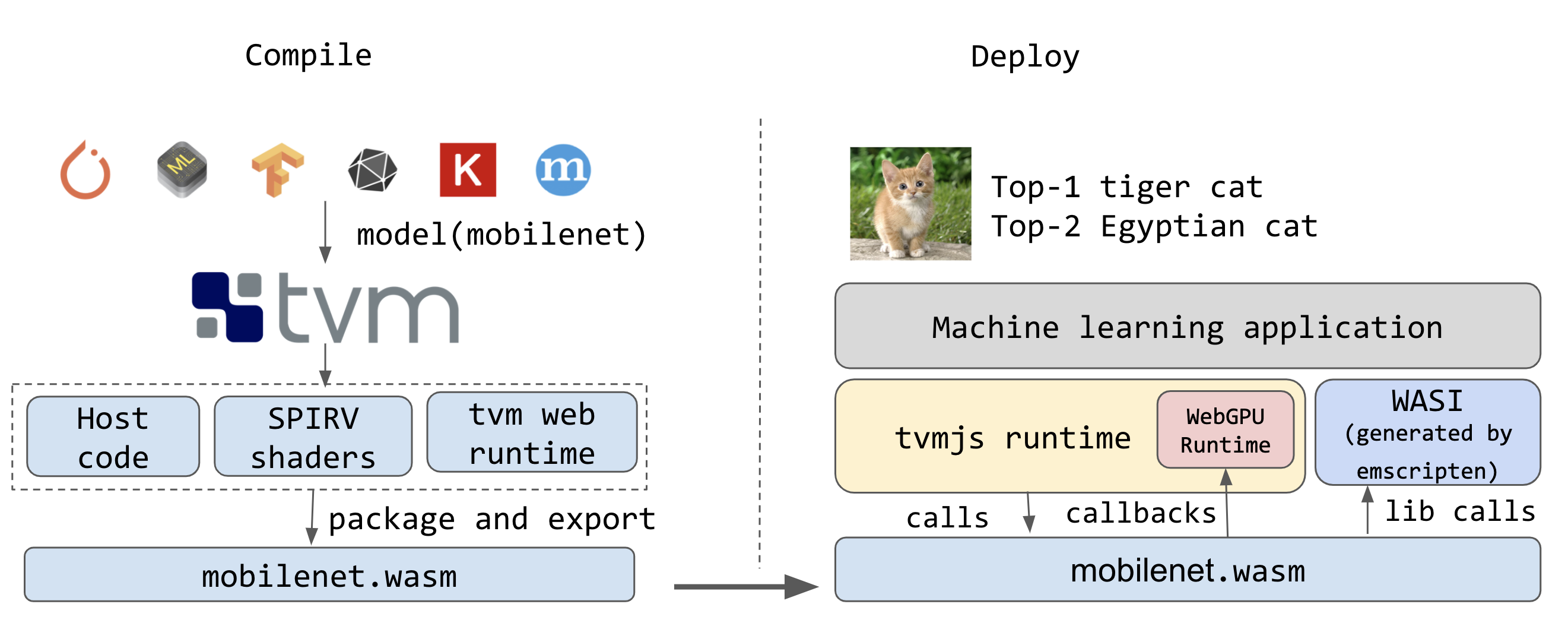
WebAssembly offers a suite of advantages that significantly augment web development, distinguishing it as a prime solution for optimizing web applications. Its foremost attribute lies in speed, facilitated by its compact binary size, which expedites downloads, particularly on slower networks. Additionally, its statically typed nature and pre-compiled optimizations markedly accelerate decoding and execution processes compared to JavaScript. Moreover, its inherent portability ensures consistent performance across diverse platforms, bolstering overall user experience. Lastly, WebAssembly's flexibility empowers developers to compile code from multiple programming languages into a unified binary format, thereby capitalizing on existing expertise and codebases while reaping the performance benefits of WebAssembly, thus streamlining and enhancing web development endeavors.
Putting it all together - Offline LLM's on mobile devices and browser!
Mediapipe and WebAssembly (WASM) collaborate seamlessly to enable Large Language Models (LLMs) on both mobile devices and web browsers, revolutionizing accessibility to vital resources.
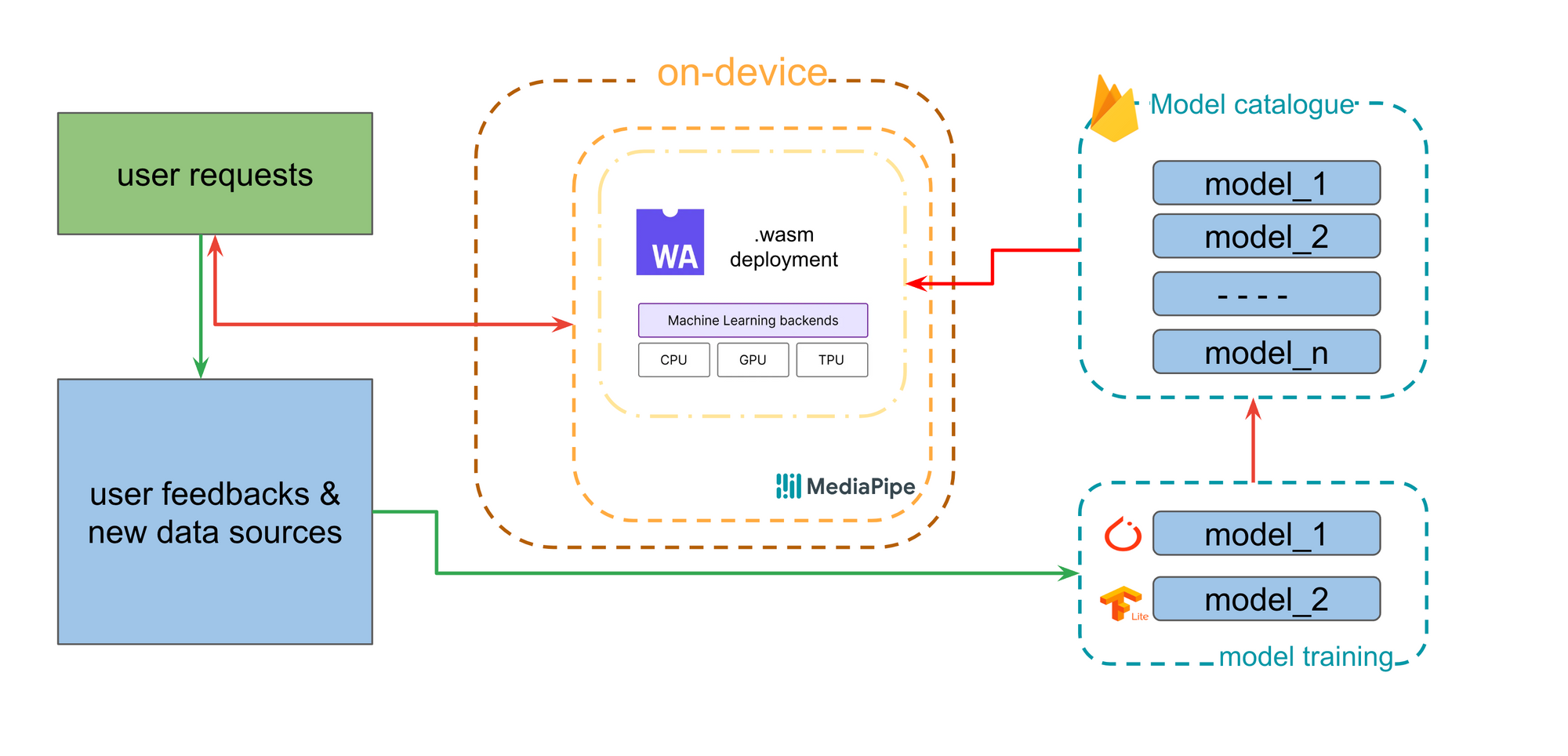
Leveraging Mediapipe's versatile ML pipeline support and WASM's platform-neutral execution environment, we've developed a robust solution that empowers users with offline access to LLMs for natural language processing tasks on nAI. Mediapipe's integration further enhances our capability by providing a streamlined framework for deploying and managing ML models, optimizing performance on resource-constrained mobile devices. Together, Mediapipe and WASM set a new standard for on-device ML inference, democratizing access to advanced language processing capabilities on a global scale, regardless of internet connectivity or device specifications.
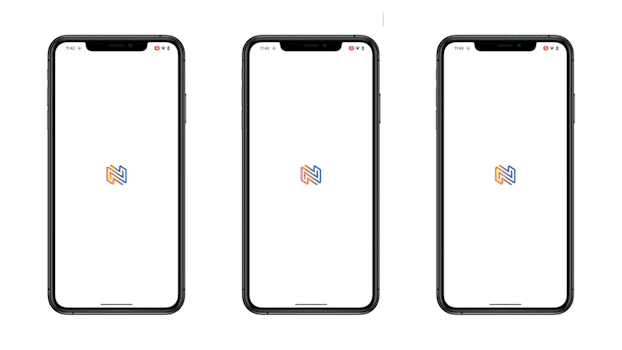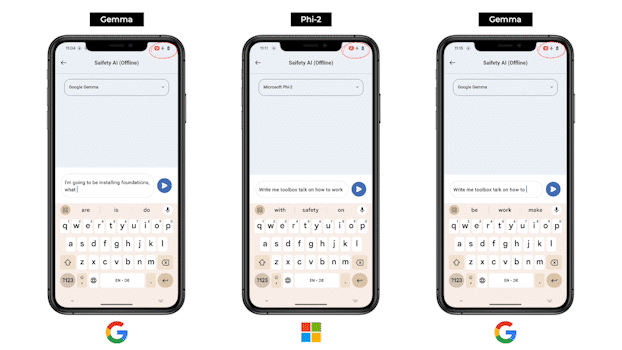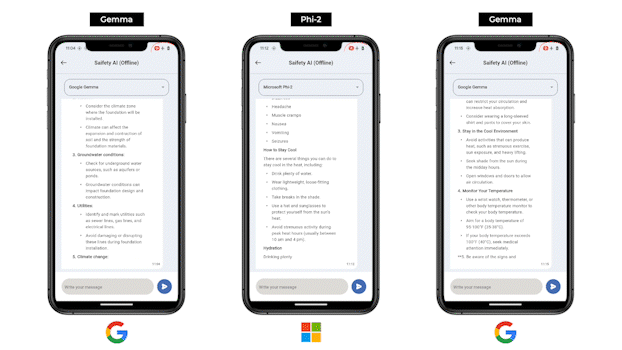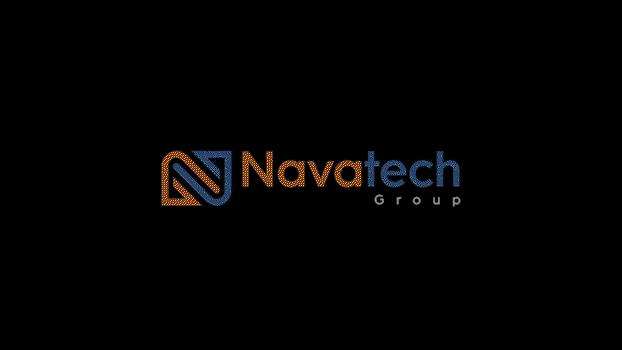
We are thrilled with the breakthrough capability, optimizations and the performance in today’s experimental release of the Offline LLM inference on nAI. This is just the start. Over 2024, we will expand to more custom models, offer broader conversion capabilities, on-device QnA, high level workflows, and much much more. Furthermore, our mobile team has pushed the boundaries of innovation by leveraging Flutter to make this groundbreaking technology to our users and make sure it is available at every hands possible . Their dedication and expertise have played a pivotal role in bringing this cutting-edge feature to our customers, ensuring a seamless and intuitive experience across mobile platforms.
Join Our Team of Innovators!

Are you a passionate developer seeking exciting opportunities to shape the future of technology? We're looking for talented individuals to join our dynamic engineering team at Navatech Group. If you're eager to be part of groundbreaking projects and make a real impact, we want to hear from you!
Send your resume to careers@navatechgroup.com and take the first step toward a rewarding career with us. Join Navatech Group today and be at the forefront of innovation!